Navigating the ETL Process: A Case Study with Movie Metadata
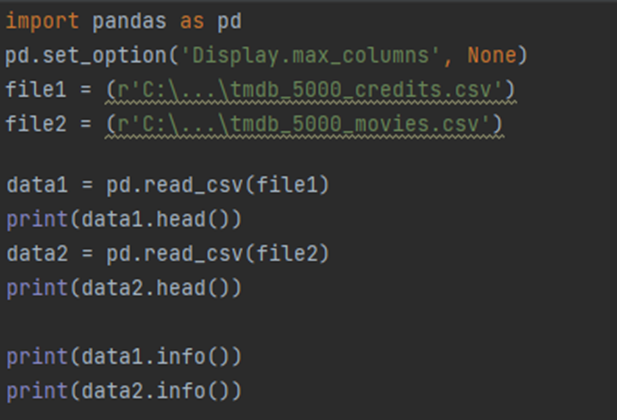
In today's entry, I delve into the ETL process (Extract, Transform, Load), focusing on extracting data from various sources, transforming it (which includes cleaning, aggregating, joining, etc.), and finally loading it into a target system. Let's begin with data extraction. For this example, I used a dataset from https://www.kaggle.com/datasets/tmdb/tmdb-movie-metadata : Both files in the dataset have an 'id' column, and after verifying, the row counts matched perfectly, confirming a consistent base for merging. Next, in the transformation phase, I combined the two files, keeping the more extensive dataset as the base. I then removed the redundant 'movie_id' and 'title' columns and renamed 'title_x' to 'title' for clarity. You can see that longer rows are presented in this way: Which makes analysis a little difficult so to see the whole we will add: Ok so let's check out what the genres column looks like: Well it is not very readab...

