Navigating the ETL Process: A Case Study with Movie Metadata
In today's entry, I delve into the ETL process (Extract,
Transform, Load), focusing on extracting data from various sources,
transforming it (which includes cleaning, aggregating, joining, etc.), and
finally loading it into a target system.
https://www.kaggle.com/datasets/tmdb/tmdb-movie-metadata:
Both
files in the dataset have an 'id' column, and after verifying, the row counts
matched perfectly, confirming a consistent base for merging.

Next, in the transformation phase, I combined the two files,
keeping the more extensive dataset as the base. I then removed the redundant
'movie_id' and 'title' columns and renamed 'title_x' to 'title' for clarity.
You can see that longer rows are presented in this way:


I extracted the data with a function because there is a chance that we will still use it further.


We still have some columns to change

Immediately better.
After checking the data type, I see that release_date is object so we will change it to date. In addition, we will remove the tagline and homepage columns because they are of no use to us for analysis. The last thing in this phase is to check the data in original_title and title because they coincide and also check what languages are in 'original_language' and also change to full names

And from the dictionary we assign to the column(some of these languages came out😊 )
Unfortunately 261 results are different, you need to analyze further. I'll check the first few instances of these differences to see what the issue is.
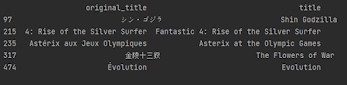
Heh well yes since we have different languages and as the name suggests one is the original title the differences are obvious 😊 For us English titles are important so we remove the original_title column
Finally, we will still check for any duplicates in the id column and we can proceed to save the data
FALSE result so great. We can save the processed file and proceed to analyze it :)


Komentarze
Prześlij komentarz